TL;DR – We are thrilled to introduce voyage-code-2
Retrieval-augmented generation (RAG), renowned for its modularity and reliability, stands as the leading approach in integrating proprietary information into LLMs. The retrieval component of RAG first vectorizes a corpus (a collection of documents) into vectors by an embedding model, and then stores and organizes these vectors in vector databases. The quality of embeddings determines the relevancy of the retrieved documents, which in turn decides the response quality of the LLMs. This underscores the importance of developing more refined and domain-specific embedding models, particularly in specialized areas such as coding, finance, law, and healthcare.
This post presents voyage-code-2
Code Retrieval via Embeddings
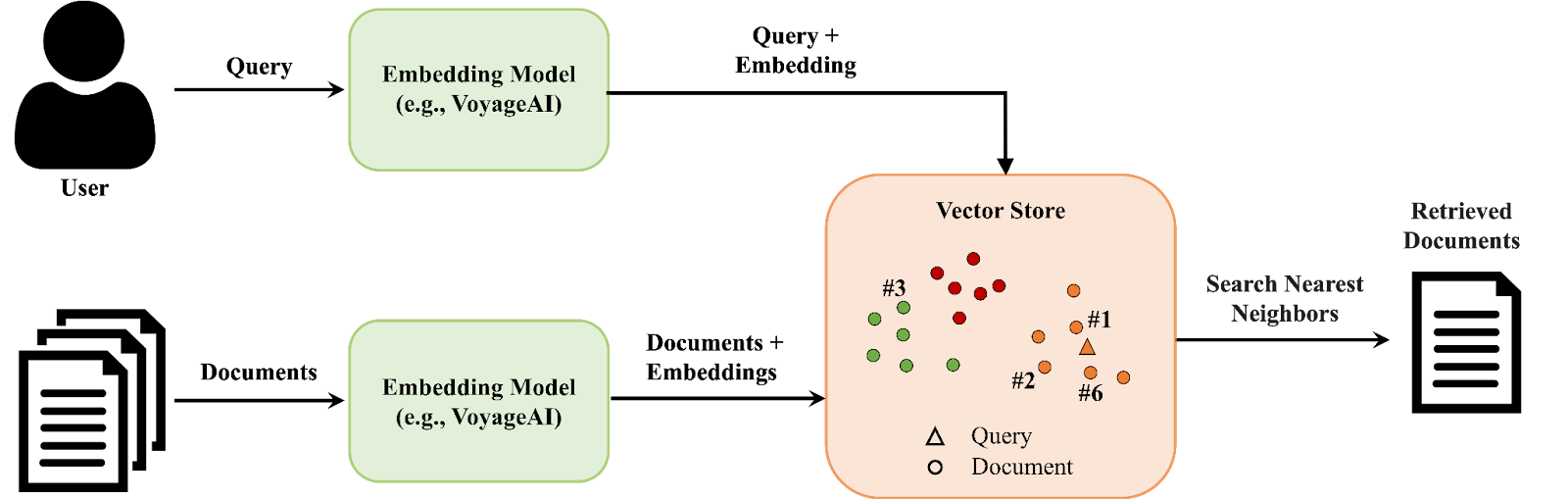
The corpus for code-related retrieval tasks is often a collection of code snippets combined or augmented with auxiliary data in natural language. A typical query is either a question phrased in natural language, a snippet of code, or a combination of both. For example, the figure below shows a query and a few code snippets in the corpus.

In this case, the most relevant snippet/document to be retrieved is #1. Note that understanding the relevance between the query and the code snippets requires deep knowledge of the functionality of the code and a semantic understanding of the natural language, going beyond mere keyword matching.
Embeddings are the most effective way to quickly retrieve relevant code from a large corpus. As shown in the figure below, embedding models turn the code snippets/documents and queries into vectors. Then, we can find the nearest neighbors of the query vector among the document vectors and return the corresponding documents.
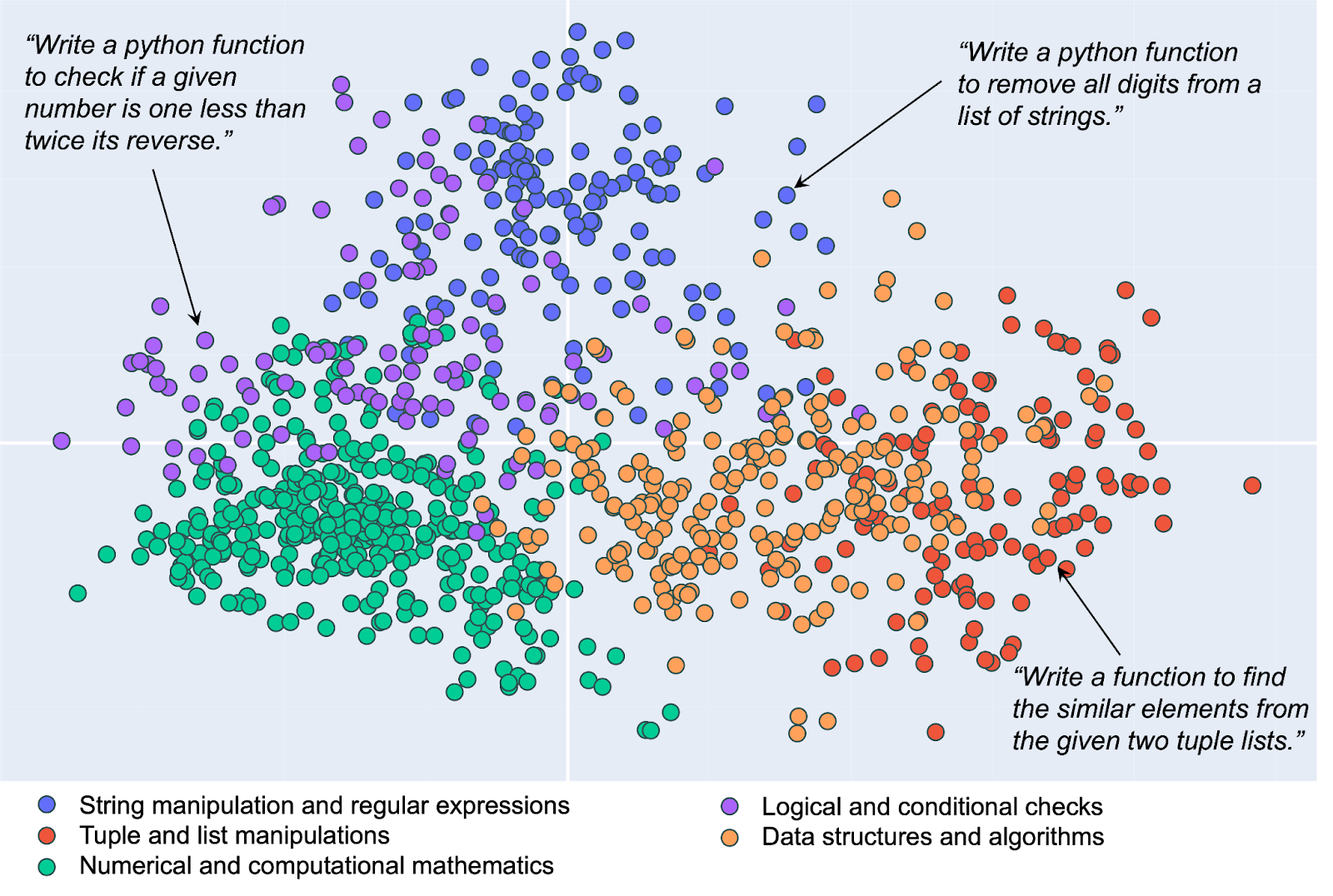
The figure below also uses real data to demonstrate how queries and documents are represented as high-dimensional vectors, which are then projected into 2D space for visualization purposes. The crucial aspect here is that similar vectors in the Euclidean space should represent semantically related documents and queries. Indeed, code snippets that are related to the same topic (indicated with specific colors) are positioned closely together.
Qualitative Comparison
This section demonstrates, through examples, the enhanced code understanding and code retrieval capabilities of voyage-code-2 compared to OpenAI Ada.
Example 1:

Both voyage-code-2 and OpenAI ada retrieved snippets that remove occurrences of a given character from the string. However, voyage-code-2
Example 2:

The voyage-code-2 accurately locates the piece of code that precisely solves the given query. OpenAI ada retrieves a related but incorrect piece of code. It replaces the value of each node in the tree with the sum of all its cousins’ values which deviates from the given query.
These examples qualitatively demonstrate that voyage-code-2 has a deeper understanding of the details in the code, enabling a superior retrieval quality compared to OpenAI ada.
Quantitative Evaluation
Evaluation Datasets. We built a suite of 11 datasets for the retrieval quality of code, using six publicly available datasets that consist of paired coding questions and solutions, including HumanEval, APPS, MBPP, DS-1000, Codechef, and LeetCode. Each retrieval dataset comprises a corpus to be retrieved from, typically encompassing all the solutions in the original datasets, and a set of test queries, usually consisting of the collection of questions from the original datasets. The gold standard document(s) for a query question is the corresponding solution(s) in the original dataset.
The datasets encompass various programming languages and packages, including Python, C++, Java, Matplotlib, Numpy, Pandas, Pytorch, Scipy, Sklearn, and Tensorflow. In total, there are 43,909 query-document pairs. The length of queries ranges from 6 to 1963 tokens, while the length of documents spans from 5 to 2003 tokens, providing a valuable measure for coding problems of varying lengths and complexities. The examples presented in the Qualitative Comparison section are from these datasets.
Evaluation Metrics. We employ recall@k, the hit rate of retrieving the gold standard document among top k retrieved documents, as the evaluation metric. Specifically, we retrieve the top-k documents with embeddings closest to the query embedding, and declare success if the gold standard document is among these k documents. We specifically use k=5, which is currently the most typical use case in downstream applications. The quality for other choices of k also improves across the board.
Voyage-code-2 Excels on Code Retrieval
In the figure below, we compare voyage-code-2 against other common embedding models from OpenAI, Cohere, and BAAI/bge on these 11 datasets with recall@5.



voyage-code-2 significantly outperforms all other models, achieving a 14.52% improvement over the next best, OpenAI text-embedding-3-large. This performance gap widens on more complex datasets like APPS and CodeChef, which require deeper code understanding. Notably, none of these datasets were encountered during our training.
Voyage Excels in Non-Coding Tasks as Well
With improved training methods on diverse datasets, voyage-code-2 also consistently improves over OpenAI, Cohere, and BAAI/bge on domains from technical documents to restaurant reviews. It exceeds OpenAI’s model by 3.03% and Cohere v3 by 4.93% in average results across all datasets.

Try Voyage Code Embedding
We provide a simple demonstration of using voyage-code-2 for code retrieval. First, follow Getting Started to install the Voyage Python package and get your API key.
Suppose you have a coding question and a corpus of code snippets available for search.
query = "Is the function dynamic_programming() implemented using dynamic programming?"
documents = [
"retriever = KNNRetriever.from_texts(documents, embeddings)",
"knn = KNeighborsClassifier(n_neighbors=3)",
"sorted_numbers = sorted(numbers)",
"def dynamic_programming(): print('yes')",
"documents_embds = get_embeddings(documents)",
"response = client.embeddings.create(input = documents, model='text-embedding-ada-002')"
]You can embed/vectorize the query and documents using the Python Voyage AI client:
import os
import voyageai
vo = voyageai.Client(os.environ.get("VOYAGE_API_KEY"))
# Get the embedding of the query
query_embedding = vo.embed([query], model="voyage-code-2").embeddings[0]
# Get the embedding of the documents
documents_embeddings = vo.embed(documents, model="voyage-code-2").embeddingsIf you are working with more than 128 documents, you will need to use a for loop to encode them. You can find the most relevant document using the k_nearest_neighbors function with k=1. Check our Tutorial for details of k_nearest_neighbors.
# Use the nearest neighbor algorithm to find the most relevant document
retrieved_embd, retrieved_embd_index = k_nearest_neighbors(
query_embedding, documents_embeddings, k=1)
retrieved_doc = [documents[index] for index in retrieved_embd_index]
print(retrieved_doc)
# Output:
# ["def dynamic_programming(): print('yes')"]You can utilize a text generation model like GPT-4 to craft a response based on the provided query and the retrieved document. Please check our Tutorial for details of implementing the RAG chatbot. You can execute the code examples provided above in the Google Colab.
Conclusions
The success of voyage-code-2 demonstrates that customizing embedding models to a particular industry and/or use case can significantly improve quality. More of these specialized models are to come — finance, healthcare, legal, multilingual, etc. As usual, we give early access to people who are interested in trying these models and providing us with targeted feedback — please contact us at [email protected] to join our newsletter and waitlist. We will keep you posted on Twitter / LinkedIn.
Leave a Reply